
칭찬 | What Is Deepseek Ai News?
페이지 정보
작성자 Shela 작성일25-03-18 00:49 조회68회 댓글0건본문
So as to make sure accurate scales and simplify the framework, we calculate the maximum absolute value on-line for every 1x128 activation tile or 128x128 weight block. We attribute the feasibility of this approach to our fine-grained quantization strategy, i.e., tile and block-clever scaling. Therefore, we advocate future chips to assist nice-grained quantization by enabling Tensor Cores to obtain scaling factors and implement MMA with group scaling. In DeepSeek-V3, we implement the overlap between computation and communication to cover the communication latency throughout computation. Furthermore, within the prefilling stage, to enhance the throughput and hide the overhead of all-to-all and TP communication, we concurrently course of two micro-batches with similar computational workloads, overlapping the eye and MoE of 1 micro-batch with the dispatch and mix of another. • Executing reduce operations for all-to-all combine. • Forwarding information between the IB (InfiniBand) and NVLink domain while aggregating IB site visitors destined for a number of GPUs within the identical node from a single GPU. • Managing fantastic-grained reminiscence format throughout chunked knowledge transferring to a number of consultants throughout the IB and NVLink area. After figuring out the set of redundant specialists, we carefully rearrange specialists among GPUs within a node based mostly on the noticed masses, striving to stability the load throughout GPUs as much as possible with out rising the cross-node all-to-all communication overhead.
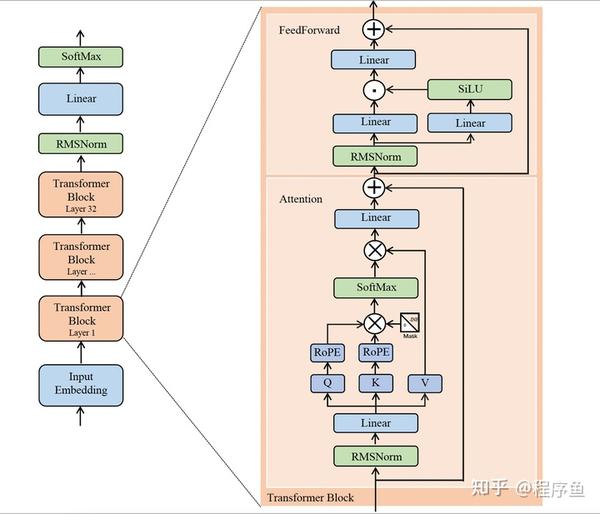
 Before the all-to-all operation at each layer begins, we compute the globally optimal routing scheme on the fly. Each of these layers features two most important elements: an consideration layer and a FeedForward network (FFN) layer. The consultants themselves are usually carried out as a feed forward community as nicely. They've some modest technical advances, utilizing a distinctive form of multi-head latent attention, numerous specialists in a mixture-of-experts, and their own simple, environment friendly type of reinforcement learning (RL), which works towards some people’s considering in preferring rule-based mostly rewards. When reasoning by instances, strong disjunctions are higher than weak ones, so you probably have a alternative between using a robust or a weak disjunction to ascertain cases, choose the sturdy one. There, they've a pleasant graphic explaining how it really works and a more in-depth explanation. This problem will change into more pronounced when the interior dimension K is giant (Wortsman et al., 2023), a typical state of affairs in giant-scale model training where the batch measurement and mannequin width are elevated. In the coaching strategy of DeepSeekCoder-V2 (DeepSeek-AI, 2024a), we observe that the Fill-in-Middle (FIM) strategy does not compromise the next-token prediction functionality while enabling the mannequin to precisely predict center textual content based on contextual cues.
Before the all-to-all operation at each layer begins, we compute the globally optimal routing scheme on the fly. Each of these layers features two most important elements: an consideration layer and a FeedForward network (FFN) layer. The consultants themselves are usually carried out as a feed forward community as nicely. They've some modest technical advances, utilizing a distinctive form of multi-head latent attention, numerous specialists in a mixture-of-experts, and their own simple, environment friendly type of reinforcement learning (RL), which works towards some people’s considering in preferring rule-based mostly rewards. When reasoning by instances, strong disjunctions are higher than weak ones, so you probably have a alternative between using a robust or a weak disjunction to ascertain cases, choose the sturdy one. There, they've a pleasant graphic explaining how it really works and a more in-depth explanation. This problem will change into more pronounced when the interior dimension K is giant (Wortsman et al., 2023), a typical state of affairs in giant-scale model training where the batch measurement and mannequin width are elevated. In the coaching strategy of DeepSeekCoder-V2 (DeepSeek-AI, 2024a), we observe that the Fill-in-Middle (FIM) strategy does not compromise the next-token prediction functionality while enabling the mannequin to precisely predict center textual content based on contextual cues.
 The DeepSeek model that everyone seemLevel Objective (SLO) for online providers and excessive throughput, we make use of the following deployment technique that separates the prefilling and decoding levels. Given the substantial computation concerned in the prefilling stage, the overhead of computing this routing scheme is nearly negligible. In the prevailing process, we need to learn 128 BF16 activation values (the output of the earlier computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written again to HBM, solely to be read once more for MMA.
The DeepSeek model that everyone seemLevel Objective (SLO) for online providers and excessive throughput, we make use of the following deployment technique that separates the prefilling and decoding levels. Given the substantial computation concerned in the prefilling stage, the overhead of computing this routing scheme is nearly negligible. In the prevailing process, we need to learn 128 BF16 activation values (the output of the earlier computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written again to HBM, solely to be read once more for MMA.
댓글목록
등록된 댓글이 없습니다.