
정보 | Take The Stress Out Of Deepseek
페이지 정보
작성자 Deon 작성일25-03-15 08:30 조회220회 댓글0건본문
This deal with efficiency turned a necessity attributable to US chip export restrictions, nevertheless it additionally set DeepSeek apart from the start. This "Floating Point Adaptive" (FPA) training balances effectivity and accuracy while lowering training prices and memory necessities. This tremendous low-degree tuning allowed them to raised match their particular hardware structure, reducing latency and bettering data switch between GPUs. After decrypting some of DeepSeek's code, Feroot found hidden programming that can send person information -- including figuring out information, queries, and online exercise -- to China Mobile, a Chinese government-operated telecom firm that has been banned from operating within the US since 2019 attributable to national safety considerations. While working for the American technology company, Ding involved himself secretly with two China-primarily based technology companies and later based his own expertise firm in 2023 centered on AI and machine studying technology. A Chinese firm has released a free automobile right into a market stuffed with free vehicles, but their automobile is the 2025 model so everybody needs it as its new. China is Apple’s second-largest market after the US. But they even have the very best performing chips in the marketplace by a long way.
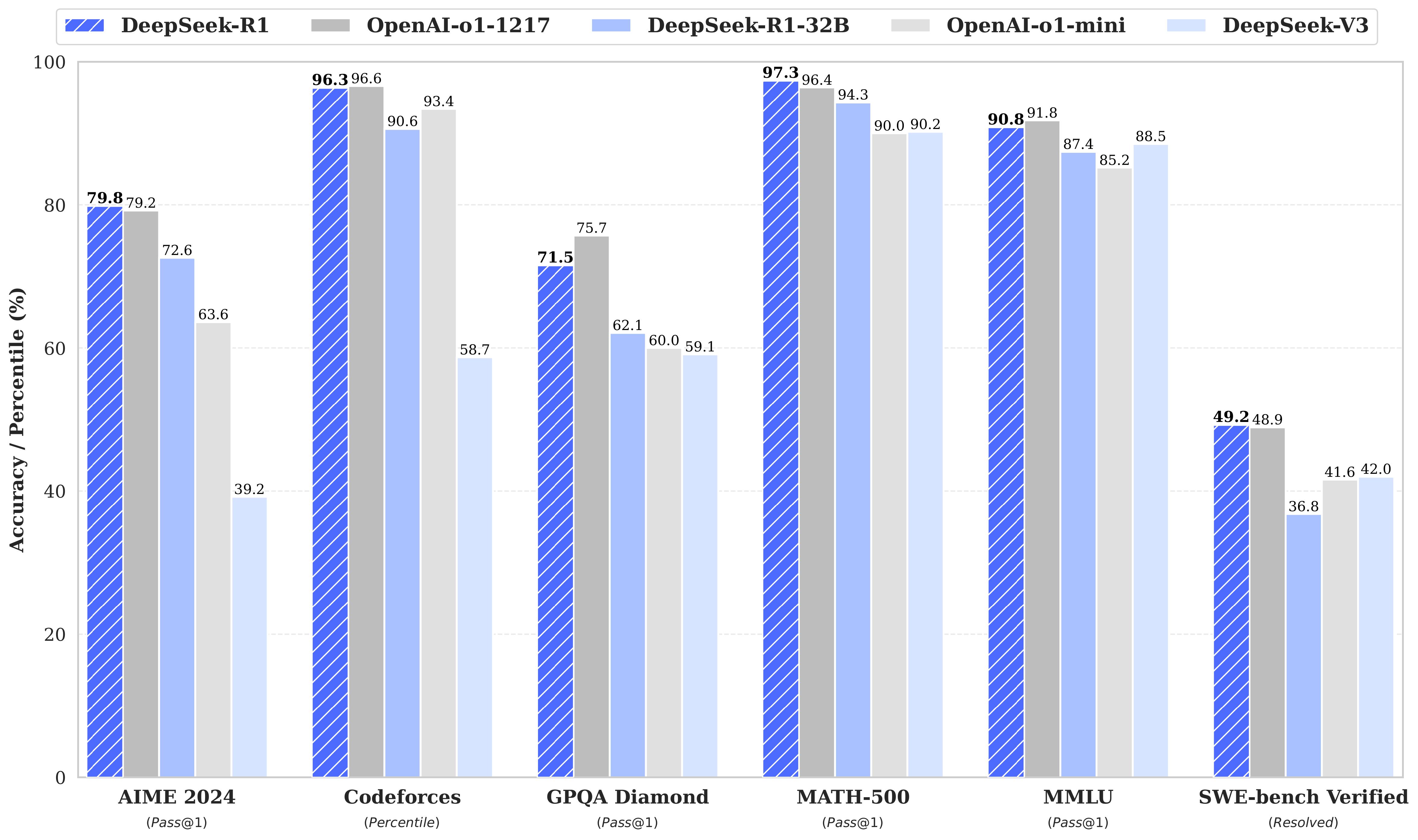 If you don't have a powerful computer, I recommend downloading the 8b model. AI safety researchers have long been involved that powerful open-source fashions could be applied in harmful and unregulated methods once out in the wild. Instead, they seem like they were rigorously devised by researchers who understood how a Transformer works and the way its varied architectural deficiencies could be addressed. It still fails on duties like depend 'r' in strawberry. Yes, it reveals comparable or better performance than some OpenAI’s fashions on several open benchmarks, however this holds true only for math and coding, it shows a lot worse outcomes for different common duties. " Well, sure and no. Yes, you need to use DeepSeek mannequin from their official API for the fraction of the cost of other common fashions like LLama. Traditional Transformer models, like those introduced in the famous "Attention is All You Need" paper, use quadratic complexity for consideration mechanisms, which means computational cost grows rapidly with longer input sequences. DeepSeek R1 uses a Mixture of Experts (MoE) structure, which means that as an alternative of activating all 671 billion parameters during inference, it selectively activates only 37 billion.
If you don't have a powerful computer, I recommend downloading the 8b model. AI safety researchers have long been involved that powerful open-source fashions could be applied in harmful and unregulated methods once out in the wild. Instead, they seem like they were rigorously devised by researchers who understood how a Transformer works and the way its varied architectural deficiencies could be addressed. It still fails on duties like depend 'r' in strawberry. Yes, it reveals comparable or better performance than some OpenAI’s fashions on several open benchmarks, however this holds true only for math and coding, it shows a lot worse outcomes for different common duties. " Well, sure and no. Yes, you need to use DeepSeek mannequin from their official API for the fraction of the cost of other common fashions like LLama. Traditional Transformer models, like those introduced in the famous "Attention is All You Need" paper, use quadratic complexity for consideration mechanisms, which means computational cost grows rapidly with longer input sequences. DeepSeek R1 uses a Mixture of Experts (MoE) structure, which means that as an alternative of activating all 671 billion parameters during inference, it selectively activates only 37 billion.
MoE introduces a brand new problem - balancing the GPU workload. While MoE strategy itself is nicely-known and already had been utilized by OpenAI and Mistral fashions, they gave an extra spin on it. Most AI fashions are educated using PyTorch, a well-liked deep-learning framework that provides ease of use however adds additional computational overhead. "DeepSeek is dirt-cheap to make use of! "DeepSeek spent 5.Fifty eight million to prepare - over 89 instances cheaper than OpenAI’s rumored 500 million funds for its o1 mannequin! "DeepSeek R1 is on the same degree as OpenAI fashions, however much cheaper! However, DeepSeek went even deeper - they personalized NCCL itself, optimizing GPU Streaming Multiprocessors (SMs) using super low degree PTX (Parallel Thread Execution) assembly language. Xiv: Presents a scholarly dialogue on DeepSeek's method to scaling open-supply language fashions. Second, new models like DeepSeek's R1 and OpenAI's o1 reveal another crucial role for compute: These "reasoning" fashions get predictably higher the more time they spend thinking. It normally starts with a random textual content that reads like a case of mistaken id.
 This turned out to be extra essential for reasoning fashions (models optimized for duties like downside-solving and step-by-step reasoning relatively than raw number crunching), which DeepSeek-R1 is. And whereas OpenAI’s system is based on roughly 1.8 trillion parameters, active on a regular basis, DeepSeek-R1 requires only 670 billion, and, additional, only 37 billion need be active at anyone time, for a dramatic saving in computation. And in third part we are going to discuss how this method was further improved and altered to make a DeepSeek-Zero after which DeepSeek-R1 model. Later in the second part you will see some particulars on their progressive method to collect data, supplied in the DeepSeekMath paper. This revolutionary approach not solely broadens the range of coaching supplies but additionally tackles privacy considerations by minimizing the reliance on actual-world information, which might often include sensitive data. Deepseek free was in a position to stabilize 8-bit coaching (FP8), drastically slicing memory utilization and increasing pace. The large tradeoff seems to be pace. Compute energy (FLOPs) - Main speed multiplier for coaching base LLMs.
This turned out to be extra essential for reasoning fashions (models optimized for duties like downside-solving and step-by-step reasoning relatively than raw number crunching), which DeepSeek-R1 is. And whereas OpenAI’s system is based on roughly 1.8 trillion parameters, active on a regular basis, DeepSeek-R1 requires only 670 billion, and, additional, only 37 billion need be active at anyone time, for a dramatic saving in computation. And in third part we are going to discuss how this method was further improved and altered to make a DeepSeek-Zero after which DeepSeek-R1 model. Later in the second part you will see some particulars on their progressive method to collect data, supplied in the DeepSeekMath paper. This revolutionary approach not solely broadens the range of coaching supplies but additionally tackles privacy considerations by minimizing the reliance on actual-world information, which might often include sensitive data. Deepseek free was in a position to stabilize 8-bit coaching (FP8), drastically slicing memory utilization and increasing pace. The large tradeoff seems to be pace. Compute energy (FLOPs) - Main speed multiplier for coaching base LLMs.
If you beloved this posting and you would like to obtain far more details pertaining to deepseek français kindly stop by the page.
댓글목록
등록된 댓글이 없습니다.